
At StanCon 2018 Helsinki, a couple of us gathered together for this thing Breck organised – birds of a feather, to discuss topics of interest with each other. I think there were about 8 of us interested in surrogate models and these are some of the notes from that meeting.
So what is a surrogate model?
Let’s say you have a function

you could approximate the function 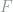
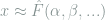
Why would you want to do this?
Some ideas we came up with are:
- When you have a complex function, which is difficult to code up but you can generate many simulations from it.
- You have a very expensive, slow function, and you need in service modelling so need results fast.
- You have no idea what the function is, you might have some data for it, but this is likely to be sparse
How do you go about doing this?
The most common methods involve some sort of interpolation:
- splines, polynomial interpolations
- neural networks
- gaussian processes
In cases where you have some sparse data and an unknown/complex function we decided that using either a probability of detection (POD) model, principle component analysis (PCA) or singular value decomposition (SVD) would be good idea.
Some food for thought
- If in our model we have something like:

and we substitute in a surrogate model

It seems like 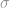
- Where do surrogate models fit into statistical models?
- How can we make surrogate models happen?
- How can this generalise to different problems?
- How can we diagnose it?
