I’m currently working on a problem where I need to sample from a very specific custom pdf. It has taken me a lot of time to get this pdf written down but now that I finally have it, I’m just missing one key ingredient… the selection function! This is when you have some underlying data (lets say some images of stars), but the observation of that data has been truncated (for example limitations of the telescope mean we can only see stars brighter than 25 mag) and then scattered by some noise. The selection function is the truncation, it is how your sample is selected from the underlying population. Generally the selection is unknown so the best way to tackle it is to fit for it.
It took me a really long time (2 days!) to sit down and figure out how to do a selection function in STAN. The problem was that I couldn’t really find any working examples on the ‘interwebs‘ but turns out that its actually really easy and really fast.
Here I demonstrate with some easy examples.
Case 1: Simple Gaussian.
First we need to generate some toy data.
nx = 1000 #number of data points in population
mu = 7
sig = 1.5
x = rnorm(nx, mu, sig) #underlying population values
cut = 6
xcut = x[which(x > cut)] #sample values after selection
n = length(xcut)
dx = 0.2 #uncertainty on x
xobs = xcut + rnorm(n, 0,dx ) #observed values
#make kernel density plot of the distributions
plot(density(x), ylim=c(0,0.4), main='', col='red', xlab='x', ylab='unnormalised density')
abline(v=cut, col=rgb(0,0,0,0.3))
lines(density(xcut), lty='dotted', col='red')
lines(density(xobs), lty='dashed')
legend('topleft', legend=c('population','sample', 'observed sample'), col=c('red', 'red', 'black'), lty=c('solid','dotted','dashed'))

The STAN model should look something like this:
mymodel <-"
data {
int n;
real xobs[n]; //observed x
real dx;
}
transformed data {
// real xcut = 6.0; //use for a fixed selection... generally selection is unknown!
}
parameters {
real xcut; //selection value
real mu;
real sigma;
real xtrue[n]; //true sample x
}
model {
xcut ~ normal(6,1);
for(i in 1:n){
/* we truncate a lower bound at xcut using T[lower,upper]. This already includes normalisation. Also note with truncation we need to do sampling in a for loop! */
xtrue[i] ~ normal(mu, sigma) T[xcut,];
}
xobs ~ normal(xtrue, dx);
}
"
We then run the code, with sensible initialisation. Pro-tip: make sure to initiate xtrue above the selection cut!
nchains = 3 #number of chains
#initialisation
init1 <- lapply(1:nchains, function(x) list(mu=rnorm(1, 7,1), sigma=rnorm(1,1.5,0.2), xtrue=rnorm(n, 8,0.1), xcut=6.0))
fit = stan(model_code = mymodel, data=list(n=n, xobs=xobs, dx=dx),
init=init1, chains=nchains, iter=2000,
control=list(adapt_delta=0.8))
You should get something that looks like this:
print(fit, pars=c('xcut','mu','sigma') )
Inference for Stan model: 4eebe5b93a44437492c76c544c69646a.
3 chains, each with iter=2000; warmup=1000; thin=1;
post-warmup draws per chain=1000, total post-warmup draws=3000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
xcut 6.01 0.00 0.04 5.93 5.98 6.01 6.04 6.08 110 1.03
mu 6.83 0.01 0.22 6.36 6.71 6.86 6.99 7.17 314 1.01
sigma 1.61 0.00 0.11 1.42 1.53 1.60 1.67 1.85 488 1.01
Samples were drawn using NUTS(diag_e) at Wed Jan 24 10:02:33 2018.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
pairs(fit, pars=c('mu','sigma'))

We can also make some posterior predictive checks, here we show some data generated from a gaussian of the fitted mean and standard deviation (black), as you can see they agree really well with the population.
params=extract(fit)
xfit=colMeans(params$xtrue)
mufit = mean(params$mu)
sigfit = mean(params$sigma)
plot(density(rnorm(n, mufit, sigfit)), col=rgb(0,0,0,0.5), lty='dotted', main='', xlab='x', ylim=c(0,0.4))
lines(density(rnorm(n, mufit, sigfit)), col=rgb(0,0,0,0.5), lty='dotted')
lines(density(rnorm(n, mufit, sigfit)), col=rgb(0,0,0,0.5), lty='dotted')
lines(density(rnorm(n, mufit, sigfit)), col=rgb(0,0,0,0.5), lty='dotted')
lines(density(x), col=rgb(1,0,0,0.5))
lines(density(xobs),col=rgb(1,0,0,0.5), lty='dashed')
legend('topleft', legend=c('true', 'observed', 'predicted'), col=c('red', 'red', 'black'), lty=c('solid','dashed','dotted') )

Case 2: Custom distribution
This is where things get a bit more tricky, but still isn’t a challenge for STAN. Before we jump into the coding, we should discuss the boring part (the math!). When we sample from a truncated pdf what we really are doing is sampling from,
![x \sim P_{[a,b]} (x) = \frac{P(x)}{\int_a^b P(u) du}](https://s0.wp.com/latex.php?latex=x+%5Csim+P_%7B%5Ba%2Cb%5D%7D+%28x%29+%3D+%5Cfrac%7BP%28x%29%7D%7B%5Cint_a%5Eb+P%28u%29+du%7D+&bg=ffffff&fg=7f8d8c&s=0&c=20201002) .
.
A lower selection limit then looks like,
![x \sim P_{[xcut,\infty]} (x) = \frac{P(x)}{\int_{xcut}^\infty P(u) du}](https://s0.wp.com/latex.php?latex=x+%5Csim+P_%7B%5Bxcut%2C%5Cinfty%5D%7D+%28x%29+%3D+%5Cfrac%7BP%28x%29%7D%7B%5Cint_%7Bxcut%7D%5E%5Cinfty+P%28u%29+du%7D+&bg=ffffff&fg=7f8d8c&s=0&c=20201002) .
.
Stan can’t do integrals numerically but it can be done by solving the ODE. Unfortunately the denominator in this is an improper integral and STAN doesn’t deal well with improper integrals so we can re-parameterise the integral in the following way:
 .
.
Now the next problem is that this integral is numerically unstable. At x=1, the integrand is infinite. To solve this we can just do a set the upper limit to a number that is a little bit smaller than 1, e.g. 0.9999.
Okay so now with the theory out of the way, we can move onto the code. We first generate again some toy data from a custom distribution:
n = 2000 #population size
x = c(rnorm(n/2, 4, 1.5), rnorm(n/2, 7,1)) #x is drawn from a mixture model
cut = 3
xsam = x[which(x > cut)]
ns = length(xsam) #sample size after selection
dx = 0.5 #measurement uncertainty
xobs = xsam + rnorm(ns, 0, dx) #observed sample
plot(density(x), ylim=c(0,0.3), main='', xlab='x', ylab='unnormalised density', col='red')
lines(density(xsam), col='red', lty='dotted')
lines(density(xobs), lty='dashed')
abline(v=cut, col=rgb(0,0,0,0.3))
legend('topleft', legend=c('population','sample', 'observed sample'), col=c('red', 'red', 'black'), lty=c('solid','dotted','dashed'))

We define the STAN model as follows:
custmodel<-"
functions {
real custom(real y, real mu1, real mu2, real sigma1, real sigma2){
//custom pdf
return 0.5*exp(- square(mu1- y) / (2 * sigma1^2) )/(sigma1*sqrt(2*pi())) +
0.5*exp(- square(mu2 - y) / (2 * sigma2^2) )/(sigma2*sqrt(2*pi())) ;
}
real[] N_integrand(real y, real[] state, real[] params, real[] x_r, int[] x_i) {
//ode to solve
real mu1 = params[1];
real mu2 = params[2];
real sigma1 = params[3];
real sigma2 = params[4];
real xcut = params[5];
real dxdy[1];
real ynew = xcut + y/(1-y);
dxdy[1] = custom(ynew, mu1, mu2, sigma1, sigma2)/square(1-y);
return dxdy;
}
}
data {
int n;
real xobs[n];
real dx;
}
parameters{
real xcut;
ordered[2] means; //ordered because mixture models have identifiability issues
real sigs[2];
real xtrue[n];
}
model{
real norm;
real theta[5]={means[1], means[2], sigs[1], sigs[2], xcut};
xcut ~ normal(4.0,1.0);
/* We have to re-parameterise the improper integral int_xcut^inf p(x) dx to int_0^1 p(xcut + x/(1-x))/(1-x)^2 dx */
norm = integrate_ode_rk45(N_integrand, rep_array(0.0,1), 0.0, rep_array(0.9999,1),
theta, rep_array(0.0,0),rep_array(0,0))[1,1];
for(i in 1:n){
target += log(custom(xtrue[i], means[1], means[2], sigs[1],sigs[2]));
if(xtrue[i] < xcut){
target+=negative_infinity();
}else{
target+=-log(norm); //normalise pdf
}
}
xobs ~ normal(xtrue, dx);
}
"
Note that the custom distribution is a gaussian mixture model. Recall in a previous post (Multivariate Gaussian Mixture Model done properly) I discussed the problems with mixture models and their identifiability issues. For this example I only run 1 very long chain for the demonstration since the Bayesian Fraction of Missing Information, I needed a lot more iterations and warm-up to achieve a good effective sample size. Here’s the results:
nchains = 1
init1 <- lapply(1:nchains, function(x) list(means=c(4.0,7.0), sigs=c(1,1), xtrue=rep(6.0,ns), xcut=3.0))
fit = stan(model_code = custmodel, data=list(n=ns, x=xobs, dx=dx), init=init1, chains=nchains, iter=5000, control=list(adapt_delta=0.8))
print(fit, pars=c('means','sigs','xcut'))
Inference for Stan model: 0ff67e36d860e76473b011bccd66c477.
1 chains, each with iter=5000; warmup=2500; thin=1;
post-warmup draws per chain=2500, total post-warmup draws=2500.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
means[1] 3.69 0.04 0.42 2.82 3.41 3.71 4.00 4.43 112 1
means[2] 6.88 0.01 0.11 6.65 6.81 6.89 6.96 7.08 156 1
sigs[1] 1.42 0.00 0.13 1.20 1.33 1.41 1.49 1.71 684 1
sigs[2] 1.04 0.00 0.07 0.93 1.00 1.04 1.09 1.18 246 1
xcut 3.06 0.01 0.09 2.86 3.02 3.07 3.13 3.21 61 1
Samples were drawn using NUTS(diag_e) at Thu Jan 25 11:08:37 2018.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
pairs(fit, pars=c('means','sigs', 'xcut'))

# posterior predictive checks
params=extract(fit)
means = colMeans(params$means)
sigs = colMeans(params$sigs)
plot(density(xobs), main='', xlab='x', ylab='unnormalised density', ylim=c(0,0.4), lty='dashed', col=rgb(1,0,0,0.5))
lines(density(c(rnorm(n/2, means[1], sigs[1]),rnorm(n/2, means[2], sigs[2]))), col=rgb(0,0,0,0.5), lty='dotted')
lines(density(c(rnorm(n/2, means[1], sigs[1]),rnorm(n/2, means[2], sigs[2]))), col=rgb(0,0,0,0.5), lty='dotted')
lines(density(c(rnorm(n/2, means[1], sigs[1]),rnorm(n/2, means[2], sigs[2]))), col=rgb(0,0,0,0.5), lty='dotted')
lines(density(c(rnorm(n/2, means[1], sigs[1]),rnorm(n/2, means[2], sigs[2]))), col=rgb(0,0,0,0.5), lty='dotted')
lines(density(x), col=rgb(1,0,0,0.5))
abline(v=cut, lty='dashed',col='red')
legend('topleft', legend=c('true', 'observed', 'predicted'), col=c('red', 'red', 'black'), lty=c('solid','dashed','dotted') )

Overall good agreement. So yeh. Selection function in STAN? Easy peasy!. Also see https://github.com/farr/SelectionExample and https://github.com/farr/GWDataAnalysisSummerSchool/blob/master/lecture3/lecture3.ipynb for some more examples!




 employees at ESA from the UK.
employees at ESA from the UK. 
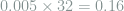 employees from Coventry working at ESA spain!
employees from Coventry working at ESA spain! 






