Michael Betancourt recently wrote a nice case study describing the problems often encountered with gaussian mixture models, specifically the estimation of parameters of a mixture model and identifiability i.e. the problem with labelling mixtures (http://mc-stan.org/documentation/case-studies/identifying_mixture_models.html). Also there has been suggestions that GMM’s can’t be easily done in Stan. I’ve found various examples online of simple 2d gaussian mixtures, and one (wrong) example of a Multivariate GMM. I wanted to demonstrate that Stan can actually do Multivariate GMM’s and very quickly! But as Mike’s already discussed problems with identifiability are still inherent in the model.
For this I will use R, but of course Stan is also available in wrappers of python, ruby and others. Firstly lets get the required libraries:
library(MASS)
require(rstan)
Then we need to generate some toy data. Working in a 4 dimensional parameter space, I want to create 3 gaussian mixtures at different locations:
#first cluster
mu1=c(0,0,0,0)
sigma1=matrix(c(0.1,0,0,0,0,0.1,0,0,0,0,0.1,0,0,0,0,0.1),ncol=4,nrow=4, byrow=TRUE)
norm1=mvrnorm(30, mu1, sigma1)
#second cluster
mu2=c(7,7,7,7)
sigma2=sigma1
norm2=mvrnorm(30, mu2, sigma2)
#third cluster
mu3=c(3,3,3,3)
sigma3=sigma1
norm3=mvrnorm(30, mu3, sigma3)
norms=rbind(norm1,norm2,norm3) #combine the 3 mixtures together
N=90 #total number of data points
Dim=4 #number of dimensions
y=array(as.vector(norms), dim=c(N,Dim))
mixture_data=list(N=N, D=4, K=3, y=y)
The model only takes a few lines of code:
mixture_model<-'
data {
int D; //number of dimensions
int K; //number of gaussians
int N; //number of data
vector[D] y[N]; //data
}
parameters {
simplex[K] theta; //mixing proportions
ordered[D] mu[K]; //mixture component means
cholesky_factor_corr[D] L[K]; //cholesky factor of covariance
}
model {
real ps[K];
for(k in 1:K){
mu[k] ~ normal(0,3);
L[k] ~ lkj_corr_cholesky(4);
}
for (n in 1:N){
for (k in 1:K){
ps[k] = log(theta[k])+multi_normal_cholesky_lpdf(y[n] | mu[k], L[k]); //increment log probability of the gaussian
}
target += log_sum_exp(ps);
}
}
'
To run the model in R only takes 1 line too. Here I use 11000 iteration steps, 1000 of which are warmup (for adaptation of the NUTS sampler parameters). I’ll use only 1 chain for speed:
fit=stan(model_code=mixture_model, data=mixture_data, iter=11000, warmup=1000, chains=1)
SAMPLING FOR MODEL '16de4bc17f41669412586868e09d4c65' NOW (CHAIN 1).
Chain 1, Iteration: 1 / 11000 [ 0%] (Warmup)
Chain 1, Iteration: 1001 / 11000 [ 9%] (Sampling)
Chain 1, Iteration: 2100 / 11000 [ 19%] (Sampling)
Chain 1, Iteration: 3200 / 11000 [ 29%] (Sampling)
Chain 1, Iteration: 4300 / 11000 [ 39%] (Sampling)
Chain 1, Iteration: 5400 / 11000 [ 49%] (Sampling)
Chain 1, Iteration: 6500 / 11000 [ 59%] (Sampling)
Chain 1, Iteration: 7600 / 11000 [ 69%] (Sampling)
Chain 1, Iteration: 8700 / 11000 [ 79%] (Sampling)
Chain 1, Iteration: 9800 / 11000 [ 89%] (Sampling)
Chain 1, Iteration: 10900 / 11000 [ 99%] (Sampling)
Chain 1, Iteration: 11000 / 11000 [100%] (Sampling)
Elapsed Time: 13.0271 seconds (Warm-up)
99.2967 seconds (Sampling)
112.324 seconds (Total)
From the results we can see we get good convergence:
print(fit)
Inference for Stan model: 16de4bc17f41669412586868e09d4c65.
1 chains, each with iter=11000; warmup=1000; thin=1;
post-warmup draws per chain=10000, total post-warmup draws=10000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff
theta[1] 0.33 0.00 0.05 0.24 0.30 0.33 0.37 0.43 10000
theta[2] 0.33 0.00 0.05 0.24 0.30 0.33 0.37 0.43 10000
theta[3] 0.33 0.00 0.05 0.24 0.30 0.33 0.36 0.43 10000
mu[1,1] -0.09 0.01 0.17 -0.41 -0.19 -0.10 0.01 0.28 751
mu[1,2] -0.01 0.01 0.16 -0.33 -0.11 -0.02 0.08 0.35 952
mu[1,3] 0.13 0.00 0.16 -0.20 0.04 0.13 0.22 0.45 3100
mu[1,4] 0.19 0.00 0.16 -0.15 0.10 0.19 0.29 0.51 2086
mu[2,1] 6.85 0.01 0.12 6.57 6.78 6.87 6.93 7.06 133
mu[2,2] 6.90 0.01 0.12 6.63 6.84 6.92 6.98 7.11 129
mu[2,3] 6.95 0.01 0.11 6.69 6.89 6.96 7.01 7.15 333
mu[2,4] 7.03 0.00 0.11 6.79 6.97 7.03 7.09 7.27 579
mu[3,1] 2.78 0.00 0.13 2.50 2.71 2.80 2.87 2.99 1704
mu[3,2] 2.84 0.00 0.12 2.56 2.77 2.86 2.92 3.05 1005
mu[3,3] 2.91 0.01 0.13 2.62 2.84 2.93 2.99 3.17 179
mu[3,4] 3.12 0.01 0.14 2.85 3.04 3.11 3.21 3.42 451
L[1,1,1] 1.00 0.00 0.00 1.00 1.00 1.00 1.00 1.00 10000
L[1,1,2] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[1,1,3] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[1,1,4] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[1,2,1] 0.73 0.02 0.41 -0.78 0.80 0.85 0.89 0.93 263
L[1,2,2] 0.54 0.00 0.11 0.38 0.46 0.52 0.60 0.83 1141
L[1,2,3] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[1,2,4] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[1,3,1] 0.16 0.08 0.77 -0.89 -0.78 0.70 0.82 0.89 97
L[1,3,2] 0.04 0.02 0.24 -0.44 -0.13 0.07 0.21 0.49 205
L[1,3,3] 0.56 0.00 0.11 0.40 0.49 0.55 0.62 0.81 7240
L[1,3,4] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[1,4,1] 0.15 0.08 0.75 -0.89 -0.76 0.66 0.80 0.88 89
L[1,4,2] 0.20 0.01 0.23 -0.27 0.05 0.23 0.36 0.65 351
L[1,4,3] 0.31 0.00 0.15 0.03 0.23 0.31 0.40 0.63 2280
L[1,4,4] 0.44 0.00 0.08 0.31 0.38 0.43 0.49 0.64 1879
L[2,1,1] 1.00 0.00 0.00 1.00 1.00 1.00 1.00 1.00 10000
L[2,1,2] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[2,1,3] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[2,1,4] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[2,2,1] 0.03 0.11 0.71 -0.87 -0.75 0.36 0.73 0.85 43
L[2,2,2] 0.69 0.00 0.13 0.49 0.60 0.68 0.77 0.98 1978
L[2,2,3] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[2,2,4] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[2,3,1] 0.45 0.05 0.59 -0.78 0.36 0.76 0.83 0.90 130
L[2,3,2] 0.00 0.04 0.39 -0.70 -0.33 0.05 0.33 0.69 89
L[2,3,3] 0.53 0.00 0.11 0.37 0.46 0.52 0.59 0.79 935
L[2,3,4] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[2,4,1] 0.25 0.07 0.68 -0.80 -0.57 0.70 0.84 0.91 89
L[2,4,2] -0.03 0.07 0.42 -0.74 -0.38 -0.07 0.33 0.72 40
L[2,4,3] -0.15 0.02 0.22 -0.55 -0.30 -0.17 0.01 0.27 122
L[2,4,4] 0.46 0.00 0.09 0.31 0.40 0.45 0.51 0.69 883
L[3,1,1] 1.00 0.00 0.00 1.00 1.00 1.00 1.00 1.00 10000
L[3,1,2] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[3,1,3] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[3,1,4] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[3,2,1] 0.45 0.04 0.59 -0.83 0.49 0.75 0.82 0.89 178
L[3,2,2] 0.66 0.00 0.12 0.46 0.57 0.64 0.73 0.96 1936
L[3,2,3] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[3,2,4] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[3,3,1] 0.58 0.08 0.55 -0.81 0.71 0.82 0.87 0.92 48
L[3,3,2] 0.01 0.03 0.28 -0.57 -0.19 0.07 0.21 0.48 121
L[3,3,3] 0.53 0.00 0.10 0.37 0.45 0.51 0.58 0.78 580
L[3,3,4] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10000
L[3,4,1] -0.44 0.06 0.64 -0.90 -0.84 -0.77 -0.51 0.87 104
L[3,4,2] -0.13 0.02 0.29 -0.59 -0.33 -0.20 0.07 0.49 236
L[3,4,3] -0.10 0.02 0.22 -0.48 -0.25 -0.12 0.05 0.35 101
L[3,4,4] 0.48 0.00 0.09 0.35 0.42 0.47 0.53 0.69 2954
lp__ -443.66 0.15 5.00 -454.49 -446.87 -443.28 -440.12 -435.03 1053
Rhat
theta[1] 1.00
theta[2] 1.00
theta[3] 1.00
mu[1,1] 1.00
mu[1,2] 1.00
mu[1,3] 1.00
mu[1,4] 1.00
mu[2,1] 1.02
mu[2,2] 1.02
mu[2,3] 1.01
mu[2,4] 1.00
mu[3,1] 1.00
mu[3,2] 1.00
mu[3,3] 1.00
mu[3,4] 1.00
L[1,1,1] NaN
L[1,1,2] NaN
L[1,1,3] NaN
L[1,1,4] NaN
L[1,2,1] 1.00
L[1,2,2] 1.00
L[1,2,3] NaN
L[1,2,4] NaN
L[1,3,1] 1.00
L[1,3,2] 1.00
L[1,3,3] 1.00
L[1,3,4] NaN
L[1,4,1] 1.00
L[1,4,2] 1.00
L[1,4,3] 1.00
L[1,4,4] 1.00
L[2,1,1] NaN
L[2,1,2] NaN
L[2,1,3] NaN
L[2,1,4] NaN
L[2,2,1] 1.02
L[2,2,2] 1.00
L[2,2,3] NaN
L[2,2,4] NaN
L[2,3,1] 1.00
L[2,3,2] 1.04
L[2,3,3] 1.00
L[2,3,4] NaN
L[2,4,1] 1.02
L[2,4,2] 1.02
L[2,4,3] 1.01
L[2,4,4] 1.00
L[3,1,1] NaN
L[3,1,2] NaN
L[3,1,3] NaN
L[3,1,4] NaN
L[3,2,1] 1.01
L[3,2,2] 1.00
L[3,2,3] NaN
L[3,2,4] NaN
L[3,3,1] 1.01
L[3,3,2] 1.01
L[3,3,3] 1.00
L[3,3,4] NaN
L[3,4,1] 1.00
L[3,4,2] 1.00
L[3,4,3] 1.02
L[3,4,4] 1.00
lp__ 1.00
Samples were drawn using NUTS(diag_e) at Tue Mar 21 10:26:33 2017.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1)
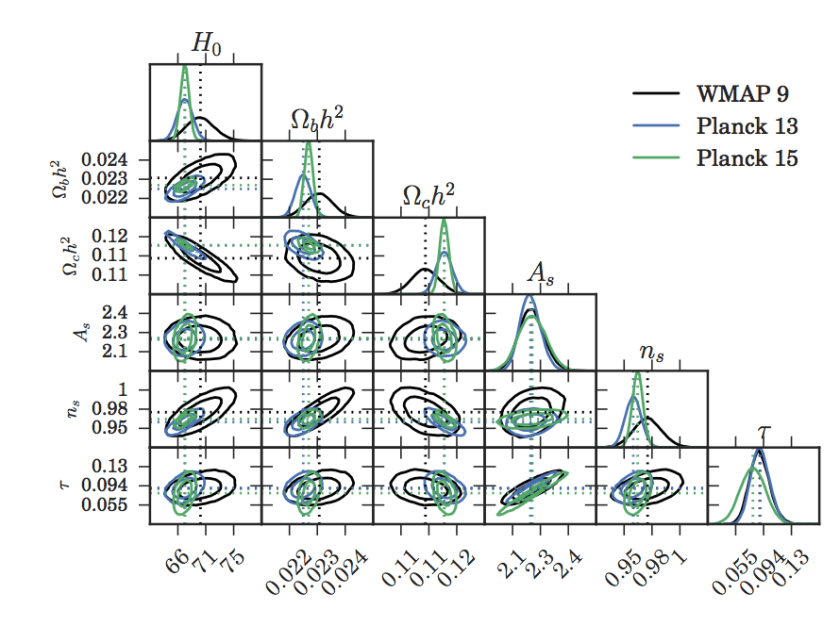
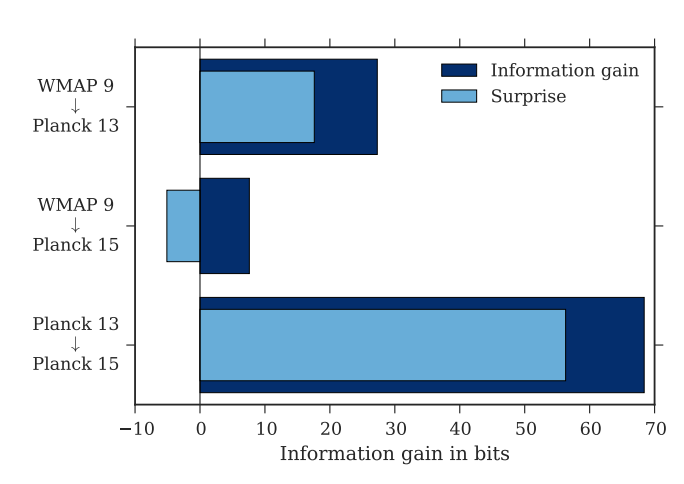
As you can see we get very good Rhat values and effective samples, also the timescale is reasonable. We recover the input parameters really well too
params=extract(fit)
#density plots of the posteriors of the mixture means
par(mfrow=c(2,2))
plot(density(params$mu[,1,1]), ylab='', xlab='mu[1]', main='')
lines(density(params$mu[,1,2]), col=rgb(0,0,0,0.7))
lines(density(params$mu[,1,3]), col=rgb(0,0,0,0.4))
lines(density(params$mu[,1,4]), col=rgb(0,0,0,0.1))
abline(v=c(0), lty='dotted', col='red',lwd=2)
plot(density(params$mu[,2,1]), ylab='', xlab='mu[2]', main='')
lines(density(params$mu[,2,2]), col=rgb(0,0,0,0.7))
lines(density(params$mu[,2,3]), col=rgb(0,0,0,0.4))
lines(density(params$mu[,2,4]), col=rgb(0,0,0,0.1))
abline(v=c(7), lty='dotted', col='red',lwd=2)
plot(density(params$mu[,3,1]), ylab='', xlab='mu[3]', main='')
lines(density(params$mu[,3,2]), col=rgb(0,0,0,0.7))
lines(density(params$mu[,3,3]), col=rgb(0,0,0,0.4))
lines(density(params$mu[,3,4]), col=rgb(0,0,0,0.1))
abline(v=c(3), lty='dotted', col='red',lwd=2)

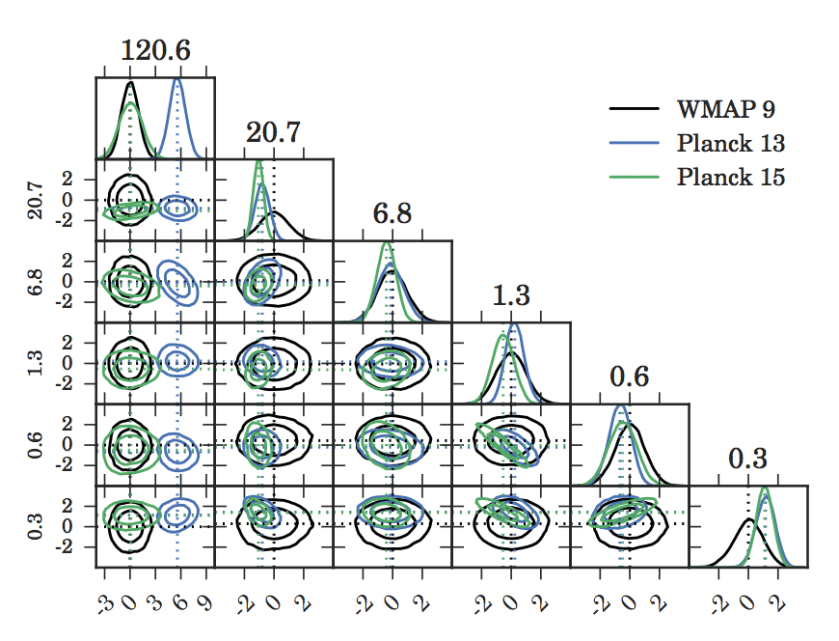
Marginalised 1D posteriors of the 3 gaussian mixture means. The red dotted line is the truth






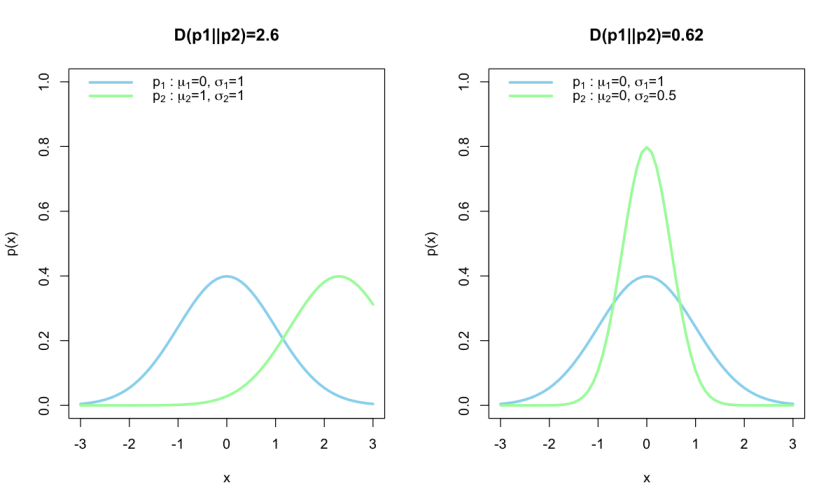
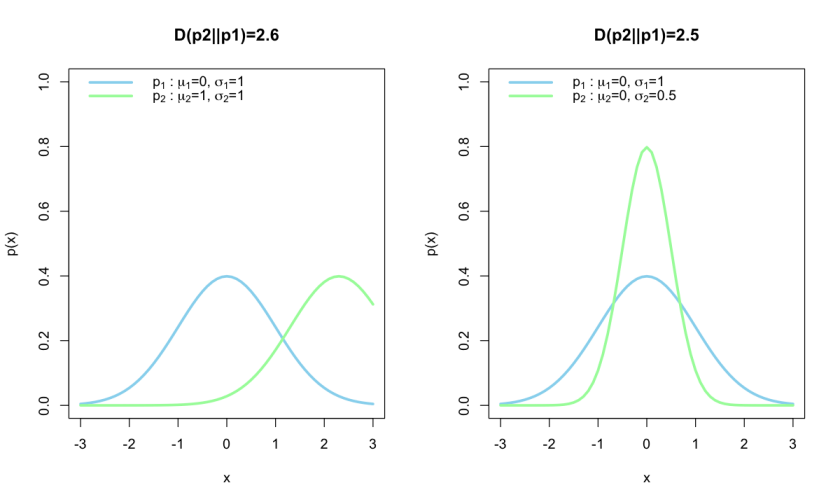
 necessarily, as we will see in the next example.
necessarily, as we will see in the next example.![D(P_2||P_1)=\frac{1}{2}[(\frac{\mu_1-\mu_2}{\sigma_1})^2 + (\frac{\sigma_2}{\sigma_1})^2+2\log(\frac{\sigma_1}{\sigma_2}) -1]](https://s0.wp.com/latex.php?latex=D%28P_2%7C%7CP_1%29%3D%5Cfrac%7B1%7D%7B2%7D%5B%28%5Cfrac%7B%5Cmu_1-%5Cmu_2%7D%7B%5Csigma_1%7D%29%5E2+%2B+%28%5Cfrac%7B%5Csigma_2%7D%7B%5Csigma_1%7D%29%5E2%2B2%5Clog%28%5Cfrac%7B%5Csigma_1%7D%7B%5Csigma_2%7D%29+-1%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)


![= \int \left[\int p(\Theta|D_1)p(D_2|\Theta)d\Theta\right] D(p(\Theta|D_2)||p(\theta|D_1)) dD_2](https://s0.wp.com/latex.php?latex=%3D+%5Cint+%5Cleft%5B%5Cint+p%28%5CTheta%7CD_1%29p%28D_2%7C%5CTheta%29d%5CTheta%5Cright%5D+D%28p%28%5CTheta%7CD_2%29%7C%7Cp%28%5Ctheta%7CD_1%29%29+dD_2&bg=ffffff&fg=7f8d8c&s=0&c=20201002)